

Anthropic is done playing prototype theater. The company just dropped Claude Sonnet 4.5—its new flagship for coding—and is pitching it not as a toy for demos, but as the model you actually wire into production. Translation: fewer “look ma, AI wrote fizzbuzz” moments, more “ship the damn feature” energy.
What Anthropic launched
Claude Sonnet 4.5 is the next major turn of the crank on Anthropic’s mid-tier workhorse, tuned hard for software development. It’s available in the Claude app and via API, and TechCrunch reports Anthropic is calling it their best coding model yet. The headline promises are what you’d expect in 2025, but with sharper edges:
- Stronger multi-file reasoning and repo-scale context, so it can keep track of what the hell is going on across services, tests and config.
- Tighter tool use/function-calling for structured, deterministic outputs and safer automation.
- Lower latency and better throughput, which matters when you’re iterating on diffs in a live codebase.
- Improved adherence to schemas/JSON modes, the boring-but-critical stuff that keeps pipelines from barfing.
Benchmarks and the “production-ready” claim
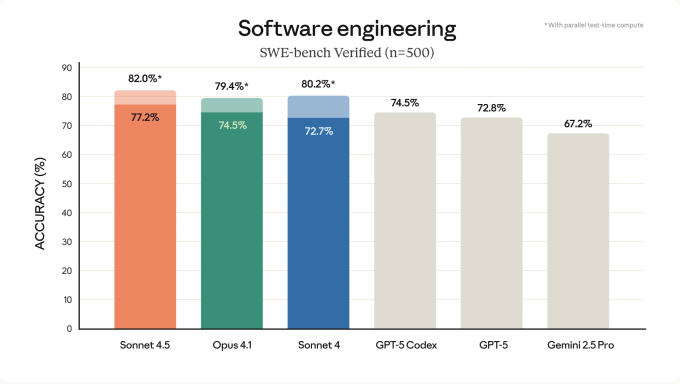
Anthropic says Sonnet 4.5 posts big gains on coding evals (think SWE-bench, HumanEval, MBPP, the usual suspects) and—this is the key point—behaves consistently enough that teams can hang real workflows on it. You can roll your eyes at benchmark chest-thumping, but reliability in tool calls, schema adherence, and long-context coherence is what separates “cute demo” from “merge this PR.”
What this looks like in practice
- Code generation that respects your house style and framework choices, not just whatever it saw on GitHub in 2022.
- Multi-step refactors with tests: propose a plan, write the changes, update fixtures, fix the fallout. Rinse, repeat.
- Repo-aware answers via project contexts, so it stops hallucinating function names that don’t exist.
- Structured outputs for CI/CD: JSON you can pipe directly into linters, test runners, or your deployment scripts without babysitting.
Anthropic’s product surface is catching up to the model, too. If you’ve used Claude’s Artifacts panel, you know the workflow: generate code, preview the output inline, iterate fast. On the integration side, Anthropic’s tool/use protocols (and the still-growing Model Context Protocol ecosystem) make it easier to plug Claude into internal tools without duct tape.
How it stacks up
- Versus GPT-4.x/o3 and GitHub Copilot: OpenAI still feels like the default in many IDEs, and Copilot’s “just do the obvious completion” UX is sticky. Sonnet 4.5’s pitch is better repo-scale reasoning, more predictable structured outputs, and competitive latency—i.e., it’s less of an autocomplete party trick and more of a junior engineer that can own a ticket.
- Versus Google’s Gemini and Codey: Google’s superpower is Workspace and first-party plumbing. If you don’t live in Google’s stack, Claude’s coding depth and guardrails are increasingly compelling.
- Versus open weights: Open-source models are catching up, especially for local code summarization and offline prototyping. For team-wide reliability and tool-calling hygiene, Anthropic’s managed route still has the edge.
Why this matters now
The last year proved a harsh truth: coding LLMs that can crank out snippets are a dime a dozen. Coding LLMs that can survive contact with your CI, your tests, and your cranky principal engineer are rare. “Production-ready” here isn’t marketing sparkle—it signals a focus on determinism, schema fidelity, and end-to-end workflows that actually survive handoff from chat window to pipeline.
The business subtext is loud, too. Enterprise buyers aren’t paying for vibes; they’re paying to:
- Shorten cycle time from spec to PR by 20–40% without exploding bug rates.
- Reduce Friday-night pages by avoiding deranged autocompletions.
- Standardize on a model that behaves the same way Monday morning as it did on Tuesday night.
Who should care
- Platform and devx teams: Sonnet 4.5’s structured outputs and tool calls make it easier to wire into linters, codemods, and template generators so you can automate the boring 60% of change requests.
- Full-stack and data engineers: Multi-file reasoning and repository context help with migrations, adapter shims, and test scaffolding—the annoying glue work that kills sprints.
- Startups: If Copilot handles your autocomplete but chokes on repo-wide changes, this is worth an A/B, especially if you’ve got a TypeScript- or Python-heavy codebase.
Early playbook to try
- Drop it into your IDE alongside your current assistant and run identical tickets for a week. Measure time-to-first-green, number of edits to pass tests, and diff size.
- Pipe it into a safe slice of CI for codemods: serialization changes, logging standardization, SDK upgrades. Use JSON/structured outputs to keep it on rails.
- Use project contexts with a subset of your monorepo to test how well it respects internal interfaces and architectural boundaries.
Caveats without the handwringing
It’s still an LLM. It will be confidently wrong sometimes, and long chains of edits can drift. The difference with Sonnet 4.5 is that its guardrails and structure make those mistakes easier to catch in tooling before they hit prod. You’ll still want tests that actually test things, reviewers who read diffs, and sane temperature settings when you care about determinism.
The bigger picture
Anthropic’s move fits the broader shift from “agent-as-demo” to “agent-as-pipeline-stage.” OpenAI is leaning into reasoners and tool use, Google is gluing AI across Workspace and Android, and challengers like DeepSeek are hammering the cost curve. Anthropic carving out the “best at coding” lane with a model that prioritizes reliability and structure is both strategically sound and, frankly, overdue.
Bottom line
Claude Sonnet 4.5 looks like a serious bid to be the default coding brain that teams trust beyond the sandbox. If you’re already paying for AI seats, run a head-to-head on your real workflows: refactors, migrations, flaky test hunts, doc generation with code references. If it cuts cycle time without spiking rework, you’ve got your answer. If not, no harm—keep your current stack and try again next quarter. In 2025, “production-ready” is a moving target; Sonnet 4.5 just moved the target closer. (via TechCrunch)

No Comments